Mitigate risk and enhance productivity with MLOps
- What is MLOps?
- Risks assessment and advantages
- People of MLOps
- Levels of automation
- A tool for MLOps: MLFLow
- Conclusions
What is MLOps?
Machine learning operations (MLOps) is quickly becoming a critical component of successful data science project deployment in the enterprise. It's a process that helps organizations and business leaders generate long-term value and reduce risk associated with data science, machine learning, and AI initiatives.
This post intends to highlight the challenges that MLOps solves and give a practical cut with an open-source tool: MLFlow.
There are several key points in the challenges that MLOps tries to solve:
-
There are many dependencies. Not only data, but also business needs are constantly changing. This means that a machine learning application must be designed to be able to adapt to changes.
-
Data scientists are not engineers. The figure of the data scientist is strongly projected on the analysis of data and on the proposition of valid solutions to the problem. Often, other figures are needed for the optimization of internal processes (data collection, performance, code reuse, etc.) and integration with other software components.
-
Standardize the development-deployment process. The packaging of complex application requires the intervention of different thematic areas and with different skills. MLOps standardizes the process, allowing all teams to easily access resources and manage the life cycle of ML capabilities.
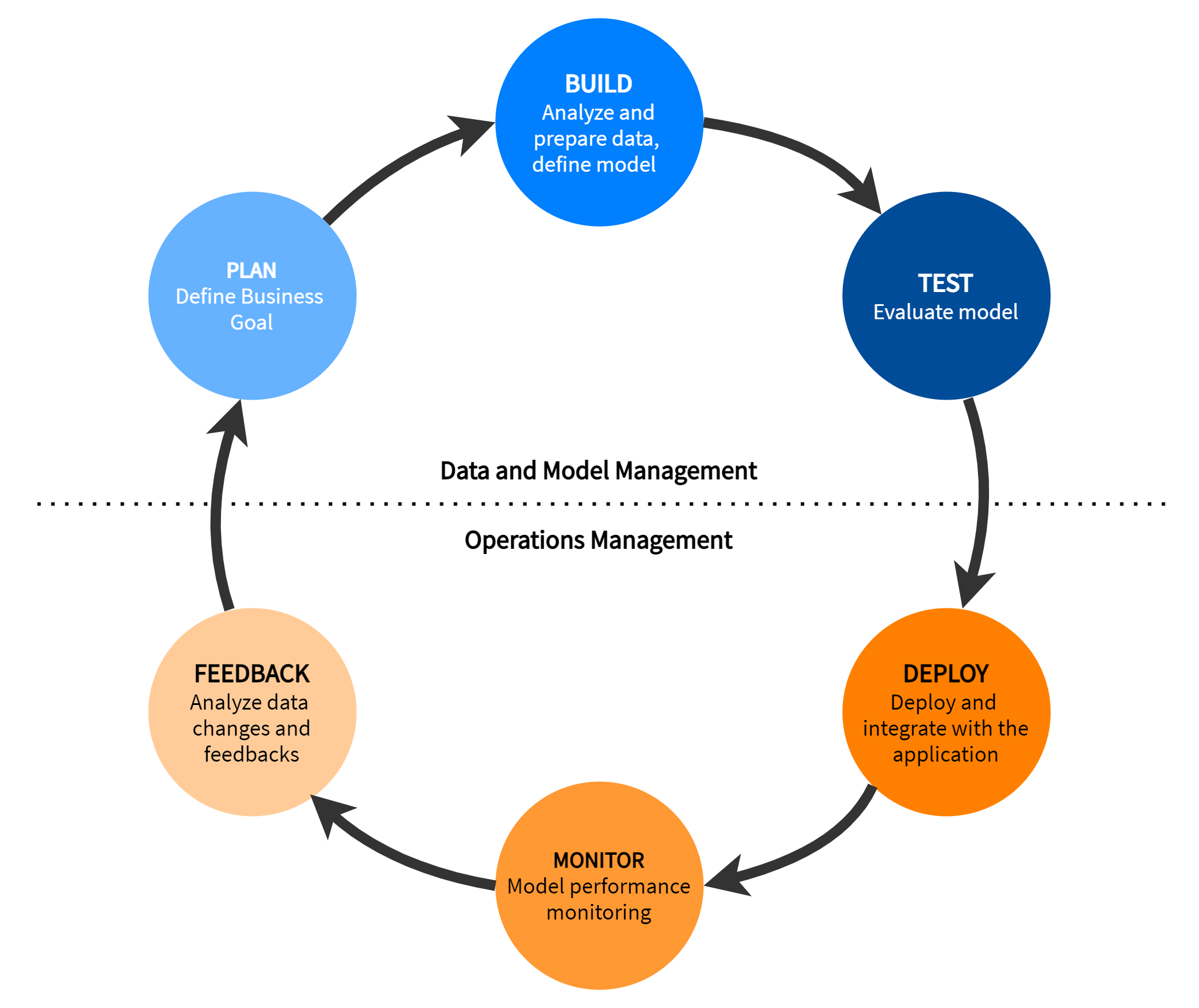
Fig. 1. The life cycle of a machine learning application. There are six stages: PLAN, BUILD, TEST, DEPLOY, MONITOR and FEEDBACK. It is a cyclical process that involves different teams and requires different skills.
Given the great challenges that a Machine Learning application brings with it, it becomes essential to automate and rationalize the development and deployment processes. In fact, when we talk about machine learning applications, we must always consider that they are complex applications, integrated with several other systems; that they have to handle large amounts of data and traffic volumes; and that the inputs of such applications are not only the application rules, but also the data. The proven DevOps tools come to the rescue: this is how MLOps was born. Although introducing MLOps processes has a cost, there are very few cases in which MLOps is not useful; the saving of money and time almost always justifies its use.
Risk assessment and advantages
The risks of a Machine Learning application are many and MLOps is a way, derived from the methodologies born of classic applications, to mitigate them. Therefore, when looking at MLOps as a way to mitigate risk, an analysis should cover:
- The risk that the model is unavailable for a given period of time
- The risk that the model returns a bad prediction for a given sample
- The risk that the model accuracy or fairness decreases over time
- The risk that the skills necessary to maintain the model (i.e., data science talent) are lost
Risks are usually larger for models that are deployed widely and used outside of the organization. Risk assessment is generally based on two metrics: the probability and the impact of the adverse event. Risk assessment should be performed at the beginning of each project and reassessed periodically, as models may be used in ways that were not foreseen initially.
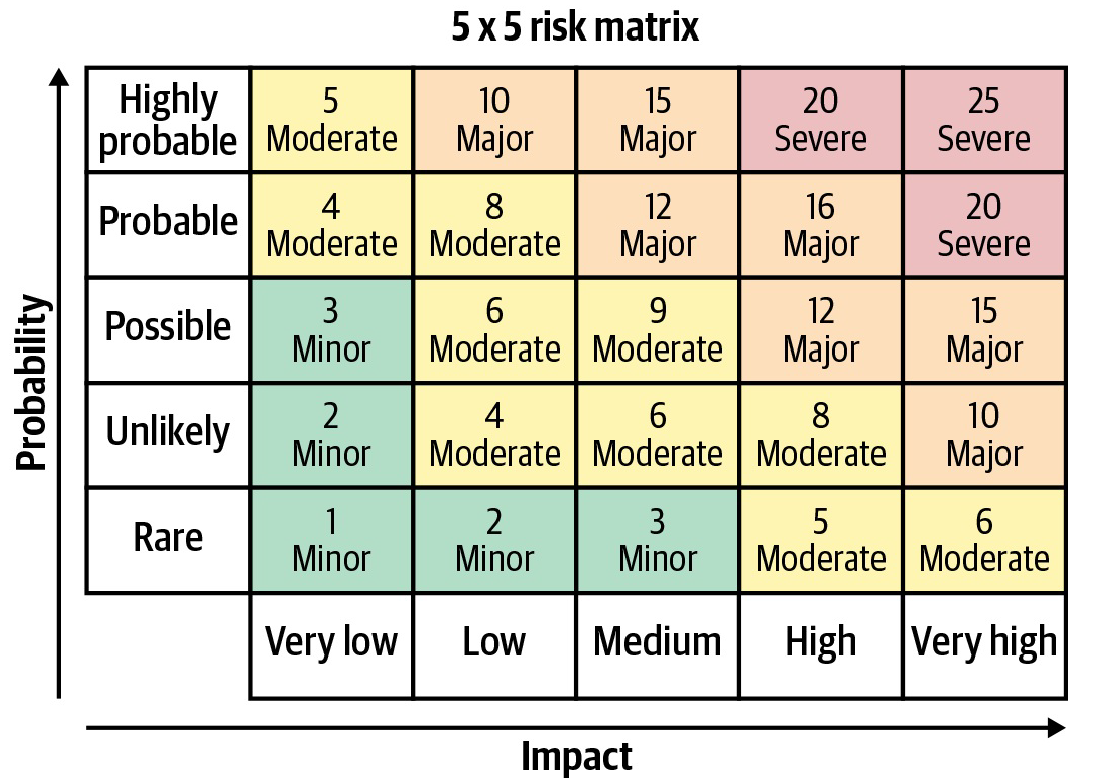
Fig. 2. The risk matrix is fundamental to understand how critical are some requirements and so how important is addressing them with MLOps.
Good MLOps practices will help teams at a minimum:
- Keep track of versioning, especially with experiments in the design phase
- Understand whether retrained models are better than the previous versions (and promoting models to production that are performing better)
- Ensure (at defined periods—daily, monthly, etc.) that model performance is not degrading in production
People of MLOps
Since an application that includes machine learning models is very complex, different professionals are involved:
-
Subject Matter Expert. is the figure who guides the entire process, defining the needs and business metrics for which a Machine Learning application must be developed. It acts in the feedback part, so it is very important that the MLOps techniques allow to extract the performance of the model also in terms of business metrics. The transformations that are carried out on the data must also be made known and easy to understand. Finally, for the Subject Matter Expert, MLOps could be useful both for Data Explainabily and for Regulatory compliance.
-
Data Scientist. The Data Scientist is a very important figure in the process. You interface with the Subject Matter Expert to translate the problem and business metrics into a machine learning problem and metrics. Furthermore, they have the arduous task of defining, understanding and finding the best settings and models for that particular problem. This can take some time and be very complicated in the case of poorly defined problems or very large applications. MLOps helps you easily monitor models in production models to guide choice in A / B testing. Plus, improve efficiency with automated model packing and deployment.
-
Data Engineers. In a machine learning process, data is the central part. Likewise, the role of data engineers is primary: they must obtain data from external sources, process it, standardize it and prepare it for algorithm training. They must interface with Subject Matter Experts to understand what types of data they need and with Data Scientists to adjust data processing according to their needs. Being a very onerous and full-time activity for large companies, Data engineers can greatly benefit from MLOps Pipelines, managing to guarantee a clean, organized and well-engineered data transformation process.
-
Software Engineers. Software engineers are equally important figures from a strategic point of view for the company. In fact, machine learning applications are experiments for their own sake, but they integrate into larger applications that involve different aspects and businesses of the company. In addition to integration, they take care of automatic testing and versioning, in order to have the CI / CD pipelines under control.
-
DevOps team. The DevOps team has two important roles. The first is to ensure the correct functioning in terms of reliability, performance, security and availability of resources and Machine Learning models with tests and operations processes. Second, they are responsible for managing the CI / CD pipeline. To do this correctly they must interface with Data Engineers, Software engineers and Data Scientists.
-
Model Risk Manager/Auditor. Model risk auditors are an essential figure especially in some critical sectors, such as financial or medical, where there are some constraints on regulatory compliance. They play a fundamental role both in defining business metrics, guiding operational research on performance and the type of machine models, and in monitoring and testing the model in production. MLOps processes allow these figures to be able to intervene rigorously when internal and external requirements are not met.
-
Machine Learning Architect. Machine learning architects are increasingly important figures for Machine Learning applications. They need to know how the data will be used and consumed in order to optimize the software architecture to improve performance in terms of speed and accuracy of predictions. Not only are they focused on data, they also need to have the right expertise to introduce new or more advanced technologies to optimize predictive models when needed. This implies that they must be aware of all the steps of the pipeline and have an overview of the shared resources in order to propose, together with the team of DevOps and software engineers, architectural solutions suitable for the business problem.
Levels of automation
After understanding the complexity of ML applications, the professionals involved and the advantages of MLOps, let's briefly illustrate the concept of pipeline, derived from DevOps principles. A Pipeline is divided into distinct subsets of activities, aimed to simplify and standardize the development and distribution of a software. Each of them constitutes a phase of the pipeline. Typical pipeline stages include:
- Build: the phase of the application in which the source code is compiled.
- Test: the stage where the code is tested. The automation allows you to save time and effort.
- Release: the stage where the application is delivered to the repository.
- Deployment: at this stage the code is deployed to the production department.
- Validation and Compliance: The steps to validate a build typically depend on the needs of the organization.
In the context of the MLOps the stages changes a bit, related more to the Machine Learning steps. For example, in a pipeline for a machine learning model creation, we have: Data preprocessing, Model Selection, Training model, Model Evaluation, Model Validation and Model Summary.
Based on the stages defined and implemented, we can identify 3 levels of automation:
- Manual Implementation.
- Continuous Model Delivery.
- Continuous Integration / Continuous Delivery of pipelines.
Manual Implementation
In this setup, everything is handled manually, without any pipeline and automation technique. This means that data scientists, data engineers and machine learning engineers manually carry out the phase of data analysis and processing, feature extraction, model choice, training, testing, validation. Once these activities have been completed, they must manually package the model in a structure that can be used and interfaced with other components and put it in a code repository. Software engineers must take the model from the code repository and manually integrate it into the application. Finally, the devops team is left with the task of monitoring the application in functional and performance terms.
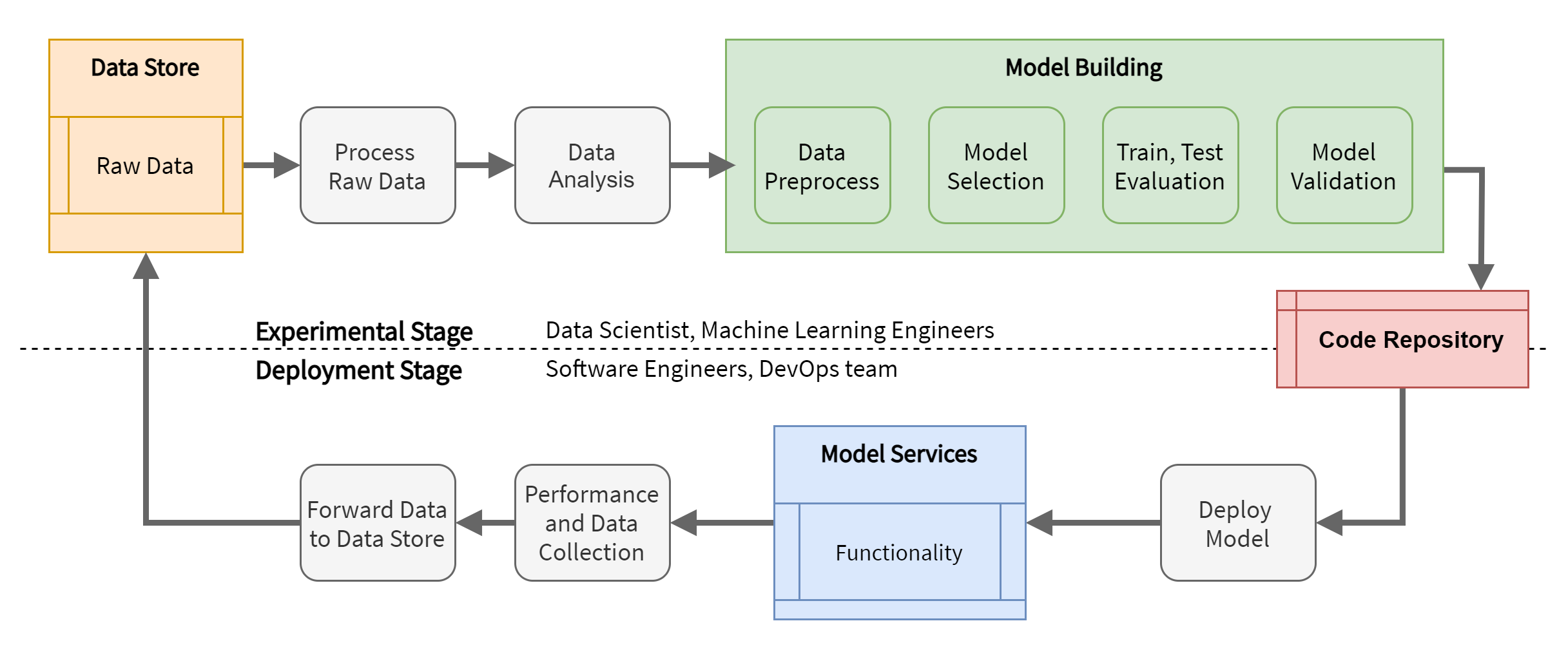
Fig. 3. The setup with no automation strategies.
All figures are involved and with the burden of doing everything manually. This implies that the setup is not resilient to changes in data and business needs: it is necessary to carry out the analysis, training, testing, integration and deployment manually.
Continuous Model Delivery
This setup includes very important elements:
-
the Feature Store, which is a data storage for training data accessible to all teams and contains the data already cleaned and preprocessed. At this juncture, we are talking about basic preprocessing, such as resizing images to the same resolution, normalizing units of measurement or creating data generators and batches.
-
Automated Model Building and Analysis, which is an engineering of the model building phase, allowing Data Scientists and Machine Learning Engineers to rely on automatic data preprocessing procedures, model selection, training, hyperparameter testing, validation and optimization. The preprocessing here refers to the adjustments on the data needed to be used by the model. The output of this process is a Modularized code, that is a well-engineered code that encapsulates a generic model and provides simple and model-independent interfaces. This allows you to standardize and automate the next steps, i.e. integration tests, deploy, etc.
-
The Deploy Pipeline, which is a pipeline designed to put the model into production. The pipeline starts from the modularized code, seen in the previous point, and carries out some preparatory steps before putting the Automated Training pipeline into operation, which will produce a working model that can be used in production.
-
The Automated Training pipeline, which is a pipeline that handles model training and produces a working trained model ready for production. The final model is placed in a Model Registry. The Automated Training pipeline is launched from the Deploy Pipeline or a Trigger and interfaces with the Feature Store to get the data that will be used for training. The trigger can be enabled manually or it can be enabled automatically by events such as the change of distribution in the data collected by monitoring the model in production.
-
The Model Registry, which is a container of trained models, accessible by all project teams. The Model Registry allows you to keep track of the various models produced, versioning them and allowing a quick comparison of their performance, discriminating the best and allowing you to automatically choose the best performing model.
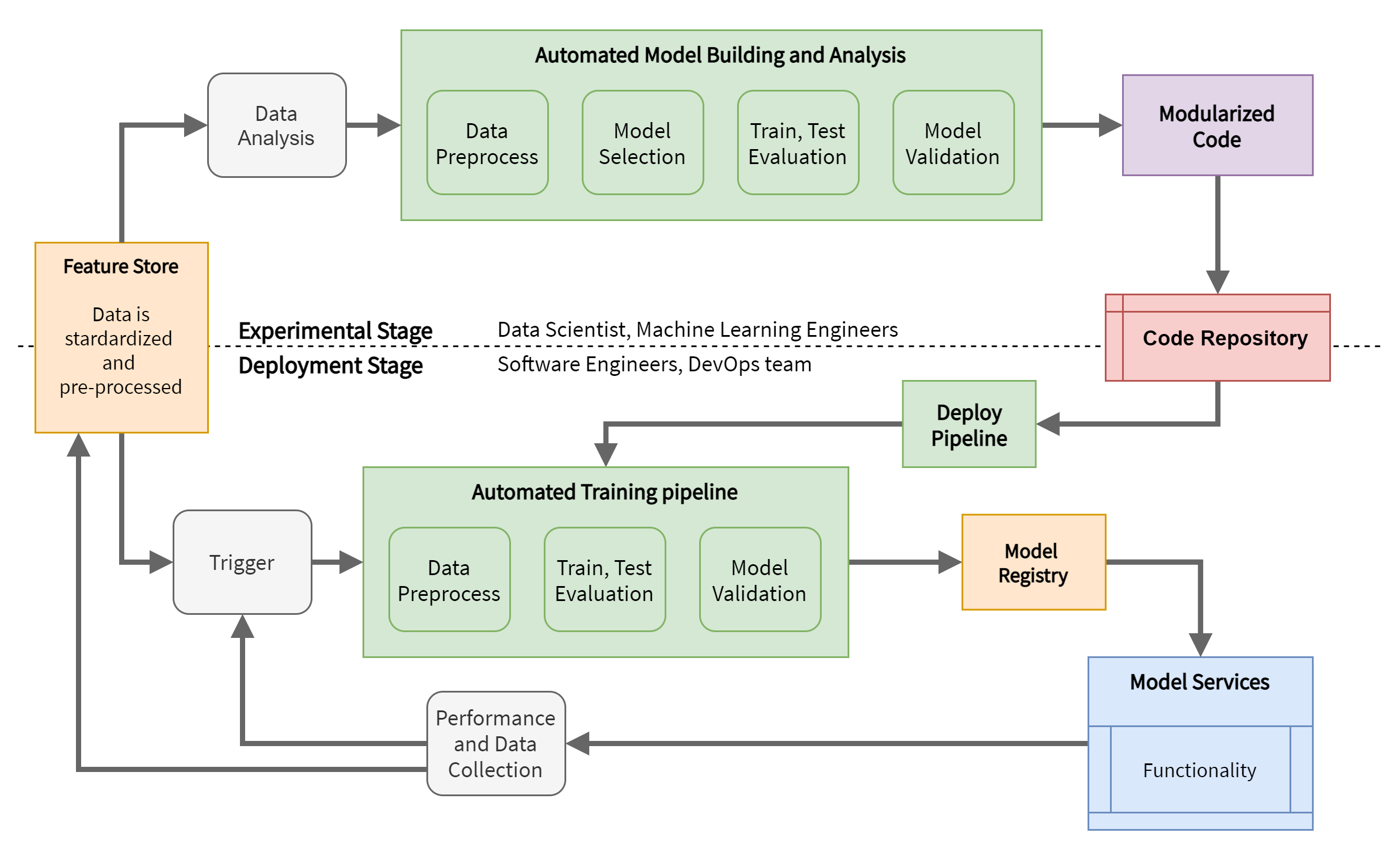
Fig. 4. The setup with Continuous Model Delivery.
With this process setting, all professional figures have control over what is happening, being able to monitor performance in a deterministic and automatic way; the greater effort on the engineering part of the code and the training and deployment pipelines reward with the creation of a more stable and faster process, capable of withstanding frequent changes on requirements or data. However, you can do better by automating the testing part of the pipelines as well. In fact, there are no mechanisms for testing and debugging pipelines automatically, and it must be done manually before it is sent to the code repository. This can become problematic and burdensome especially when there are multiple models and different architectures with different ways of data preprocessing, training and testing. Letting testing and debugging manually can become a bottleneck and be risky. Also, pipelines are not automatically deployed. This implies that if the structure in the code changes, engineers must rebuild parts of the application to make it compatible with the new pipeline and its modularized code. Modularization, in fact, only works without problems when all components know what to expect from each other; as soon as one of the components is no longer compatible, the application must be rebuilt to accommodate the new changes or the component must be rewritten to work with the original pipeline.
Continuous integration / Continuous delivery of pipelines
This setup introduces other improvements:
-
Testing, to be able to automatically test code building pipelines and package only those pipelines that pass the tests. The tests, at this juncture, could be related to the verification of the inputs and outputs of the pipeline, of the ranges of the hyperparameters, if the scaling or normalizations on the data have occurred correctly (both in preprocessing and in postprocessing), etc. Therefore this phase is fundamental in order to deliver complete and correct pipelines in the ** Package Store ** that can also be reused on different domains and with very different neural network architecture.
-
The Package Store is a pipeline container. It is optional but included in this configuration so that there is a centralized area where all teams can access packaged pipelines ready for deployment. The model development teams push in this package repository and software engineers and DevOps teams can retrieve a packaged pipeline and deploy it. It works in a very similar way to the Model Registry as both elements help to achieve continuous delivery.
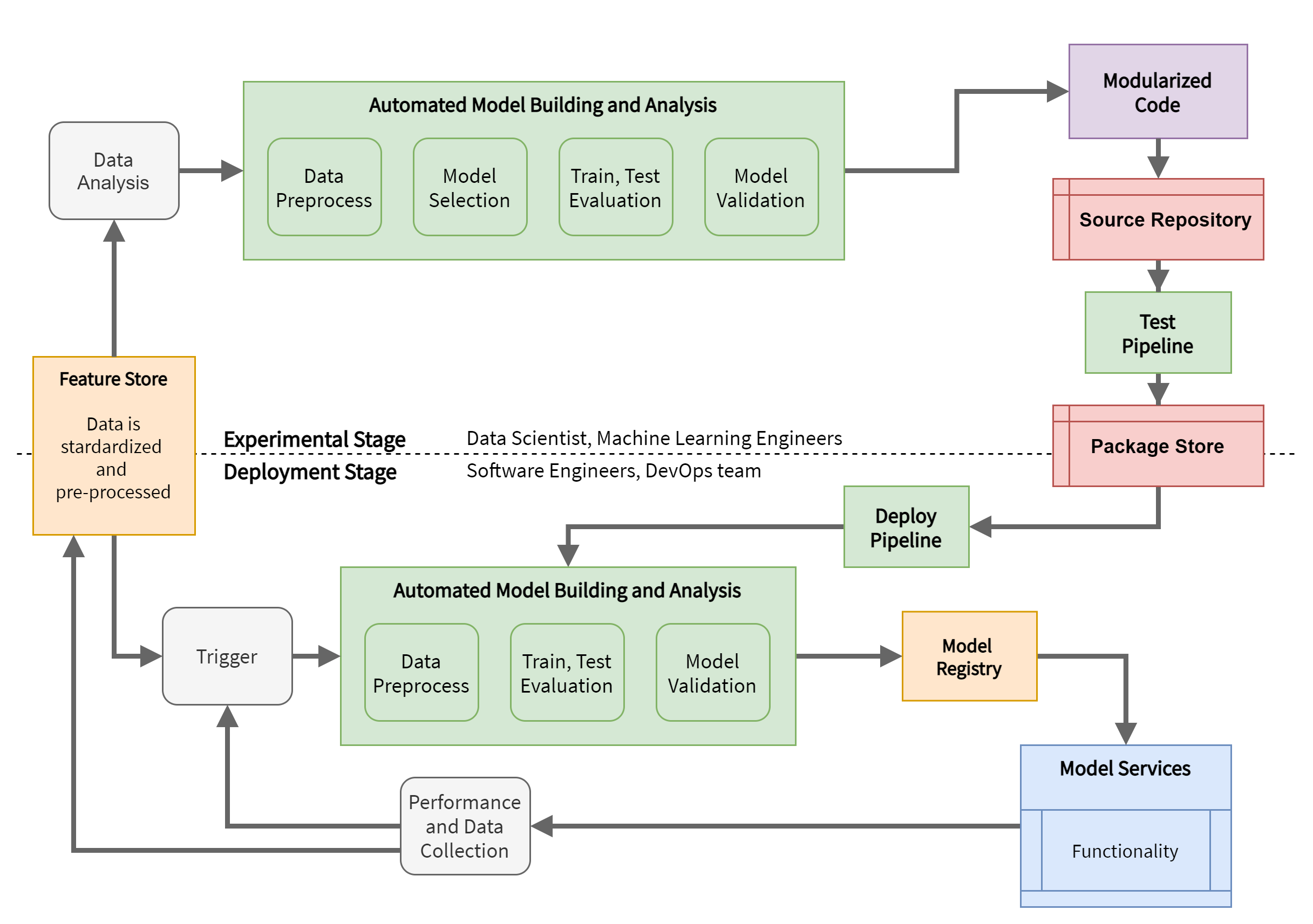
Fig. 5. The setup with Continuous Integration / Continuous Delivery of pipelines.
This is the most complete setup that allows you to absorb even important changes on specifications and data. It is a completely generic setup that can also be reused for other projects or products and therefore it is worth spending some resources to set up this mechanism.
A tool for MLOps: MLFLow
After having seen the key aspects of the MLOps processes, let's try to give a practical footprint. MLFlow is an open-source tool, easy to integrate in your existent machine learning processes. Only few lines of code are needed to track all of the metrics you need. Furthermore, MLFlow saves the models, allowing for future use in deployment or model serving functionality in a simple manner. You can also compare all of the metrics between the individual models to select the best one. MLFlow also integrates into Databricks, AWS SageMaker, Microsoft Azure, and can be deployed to Google Cloud as well, all of which are tools that help manage your MLOps setup and serve as platforms to deploy your models on. While the cloud platforms do provide some MLOps functionality, with the extent of this varying for each platform, the advantage of using MLFlow is that it lets you have the freedom of choice when it comes to one platform to commit to.
So, the main benefit of using MLFlow is that, for free, you can start managing your machine learning experiments locally and translate everything to the cloud with minimal effort. This is useful both for the data scientist who works independently and for small to medium-sized companies with a limited budget.
One of the best features of MLFlow is that the automatic management of modularization we have seen previously. This allows you to manage very different models equally, even belonging to different libraries such as Tensorflow, PyTorch, Scikit-learn or PySpark. In fact, MLFlow creates a sort of wrapper around the model in order to standardize the user experience in the deployment and prediction phase: to use it, simply transform the data into a certain format and execute REST calls on the endpoint provided by MLFlow. The latter in fact also allows the deployment of a model save with a simple API.
In general, MLFlow has several features that support the life cycle of a machine learning application:
-
Creating experiments: Experiments in MLFlow allow you to group your models and any relevant metrics. This is important, for example, for comparing the same model with different dataset or for comparing models from different libraries, such as Tensorflow or PyTorch to see which one is more performing.
-
Model and metric logging: MLFlow allows you to save a model in a modularized form and log all of the metrics related to the model run. A model run is a composed of several steps (usually model training, testing and validation), in which you can write custom code. You can mark the start and the end of each run and decide which metrics you want to log. Additionally, you can save images, graphs, plots (such as confusion matrices and ROC curves) for a successive comparison.
-
Comparing model metrics: With an easy to use web interface, MLFlow allows you to compare different models, settings and their metrics all at once also in a singular experiment. This could be very useful when performing validation to tune a model’s hyperparameters. In a moment, you can compare all of the selected metrics and choose the best.
-
Model Registry: MLFlow implements a model registry functionality, helping to define what stage a particular model is in. T o make the most of the feature, you have to integrate it with other platforms which provide built-in model registry feature, such as Databricks.
-
Local deployment: MLFlow allows you to deploy on a local server by exposing an endpoint on which doing REST call. This permits to easily test model inference. Data is sent to the model in one of several standardized formats and it returns the predictions made by the model. Such a setup can easily be converted to work on a hosted server or cloud-provided server as well. The only difference comes with where you host the model and the particular procedure for querying it.
I will not go into the merits of integrating MLFlow into existing code; the purpose of this post is not to be a practical guide. Software tends to change over time, and it would no longer be a general post. For information, you can refer to the MLFlow documentation which will be increasingly updated and more reliable than this post. The intent is to show that there is the possibility of using automation and monitoring tools locally, with minimal costs and enormous advantages.
Conclusions
DevOps techniques were born to make the development and distribution of classic applications more efficient and organized. The automation of these processes is a fundamental step to face the complexity of these applications, which is constantly growing. In fact, they often provide different levels of persistence, integration with other systems, an ever-increasing number of microservices, API Gateways, unified identity providers for multiple applications, etc. The MLOps techniques have been derived from the former and specifically aimed at applications that include Machine Learning models. Such applications hide more challenges and pitfalls than traditional applications. This is because ML models require more resources and are dependent on two inputs: business rules and data. Data is a very important part of the process and, just like business needs, they are constantly changing.
Furthermore, it should be remembered that machine learning applications do not live alone, but are always an integral part of traditional applications, which makes the entire application difficult to manage without automation and pipeline techniques.
Precisely for this reason, many people with different skills and responsibilities are involved in the development process of an ML application: Subject matter experts, Data Scientists, AI and data engineers, Software Architects, DevOps Engineer and Model risk managers/auditors. Tools such as the model registry and a shared data/feature store allow all teams in the game to be aligned and able to discern the version of the model in production, making the development and distribution chain accessible to all.
As the last step of this post, we took a look at MLFlow. It is an open-source tool that can be used locally to test parts of pipelines, organize work and code to support monitoring and automated model deployment at no cost. With the wrappers towards Databricks, AWS SageMaker and Azure Machine Learning it is immediate to translate to cloud processes and architectures.