Improving Skeletonization through GANs
- Introduction
- Why Skeletonization is so important
- Using GANs to transform images
- Results and Improvement points
- Conclusions
Introduction
In recent months, I have begun to structure a new skeletonization method which,
as you can understand from my previous article,
is the most delicate step of the off2on framework, that means recovering an online handwriting
from its offline counterpart. Online or dynamic handwriting specimens are acquired with
a digital tablet and contain the time functions of the pentip position and the pressure during
their execution. Offline or static ones are obtained by scanning documents and stored as images
and clearly they lack of temporal information.
The idea is that skeletonization is conceptually difficult and there are many patterns to manage. However, a neural network can also learn patterns that would be hidden to the human eye. I thought I'd train a Pix2Pix GAN to do the stroke-to-pen-to-skeleton conversion.
Below is an image showing the result:

Fig. 1. Images related to skeletonization. Above those of reference: in particular, on the left we find the original one, on which the skeletonization algorithms operate; on the right, the ideal, expected result obtained with the Bresenham algorithm. Below, the result obtained by two skeletonization algorithms: on the left the one obtained with a traditional skeletonization algorithm; on the right the one obtained with GANs.
At the top left there is an image of a signature acquired by an electronic tablet and obtained through an ink deposition algorithm. It represents the starting point, such as a handwritten signature on a piece of paper. We start from the data collected electronically to have the ability to generate the image at the top right, or our expected, through the Bresenham algorithm. In the lower left, there is the image showing the result of a traditional skeletonization algorithm on the original image (i.e. the one in the upper left). We can see that it is very far from the ideal. Finally, at the bottom right, is the result obtained with a GAN trained on very few samples. In this case, the result is not excellent, but it has captured features closer to the desired result.
Why Skeletonization is so important
Skeletonization provides a compact yet effective representation of 2-D and 3-D objects, which is useful in many low- and high-level image-related tasks including object representation, retrieval, manipulation, matching, registration, tracking, recognition, and compression. Also, it facilitates efficient characterization of topology, geometry, scale, and other related local properties of an object.
In the field of handwriting recognition and signature verification, it plays an even more important role. This has been abundantly underlined in the post A novel Writing Order Recovery Approach for handwriting specimens, in which I show that the writing order recognition algorithm I designed works well on the ideal skeleton. On a skeleton obtained with traditional skeletonisation methods, on the other hand, the performance is significantly lower. This is due to the fact that current skeletonization algorithms produce artifacts that tend to manipulate the image and hide precious details that would favor the recovery of the writing trajectory.
Furthermore, recovering the trajectory would be of fundamental importance for many other applications
such as the study of the effects of Parkinson's and Alzheimer's on handwriting. Therefore, having
a performing skeletonization algorithm would allow to progress on the off2on framework studies and
obtain important results on related applications.
Refer to this article
for more details about the off2on framework and recovering strategies.
Using GANs to transform images
Studying the Generative Adversarial Networks, I came across a particular type of these, called Pix2Pix, to carry out image transformation. The approach was presented by Phillip Isola, et al. in their 2016 paper, titled “Image-to-Image Translation with Conditional Adversarial Networks” and presented at CVPR in 2017. In particular, the aim was to obtain stylized images of Google maps from satellite ones.
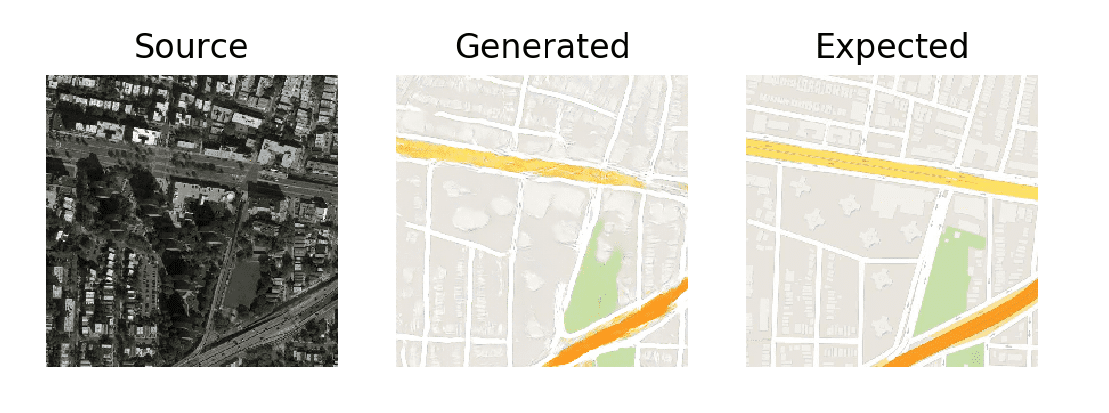
Fig. 2. Output described in the "Image-to-Image Translation with Conditional Adversarial Networks" paper, operating on satellite images.
The GAN architecture is composed of a generator model, for creating new plausible synthetic images, and a discriminator model, which classifies images as real or fake.
The Pix2Pix model is a type of conditional GAN, where the generation of the output image is conditional on an input, in this case, a source image. The discriminator is provided both with a source image and the target image and must determine whether the target is a plausible transformation of the source image.
The discriminator model weights are updated directly, whereas the generator model ones are updated via the discriminator. In detail, the two models are trained simultaneously in an adversarial process where the generator tries to better fool the discriminator and the discriminator aims to better identify the counterfeit images.
The generator is trained via adversarial loss, which encourages the generator to generate plausible images in the target domain. The generator is also updated via L1 loss measured between the generated image and the expected output image. This additional loss encourages the generator model to create plausible translations of the source image. The generator is an encoder-decoder model using a U-Net architecture. It means that skip-connections are added between the encoding layers and the corresponding decoding layers, forming a U-shape. I recommend that you read the paper for an in-depth look at GANs and the type of architecture used.
Given the good results obtained in the paper, I decided to use the same architecture on a potentially simpler task: skeletonization, which is still unsolved today.
Below, there are some sources I used to setup the project:
The idea is to use, as training set, images composed of the concatenation of a real handwritten image and the skeletonized corrispective. As a skeletonized image, I used the one generated by the Bresenham's algorithm, which for us is the ideal skeletonization.
The Pix2Pix GAN architecture proposed in the paper accepts only images of 256x256 pixels. I kept this size with the purpose to be easier to train, in terms of number of samples and time. As the GAN requires a fixed size input, the variability of the image size was managed by adding white padding and breaking the image into patches of 256x256 pixels. The output is obtained by converting each patch individually and recomposing the image.

Fig. 3. An example of a signature larger than 256x256 pixels, to which padding has been added and split into patches of the required size.
Results and Improvement points
I have trained the model for 100 epochs and with only 20 samples.
The goal was to conclude the tour to verify its feasibility and share these first results with
the University of Salerno to allow them to continue the experiments on the off2on framework.
This means that the model has a lot of room for improvement:
- using a larger dataset will certainly allow for better results;
- a study on the hyperparameters of the model must be carried out; in this regard it is also important to define an optimization function, something not taken for granted on GANs;
- thinking about the modification of the architecture of the generator model.
As you can see, in fact, the conversion is not perfect. Despite this, it can be noted that
clusters/intersections are managed "better" than traditional skeletonizations. Refer to Fig 4.
and focus on intersections, where the >--< pattern, tipical of traditional skeletonization,
is not created.
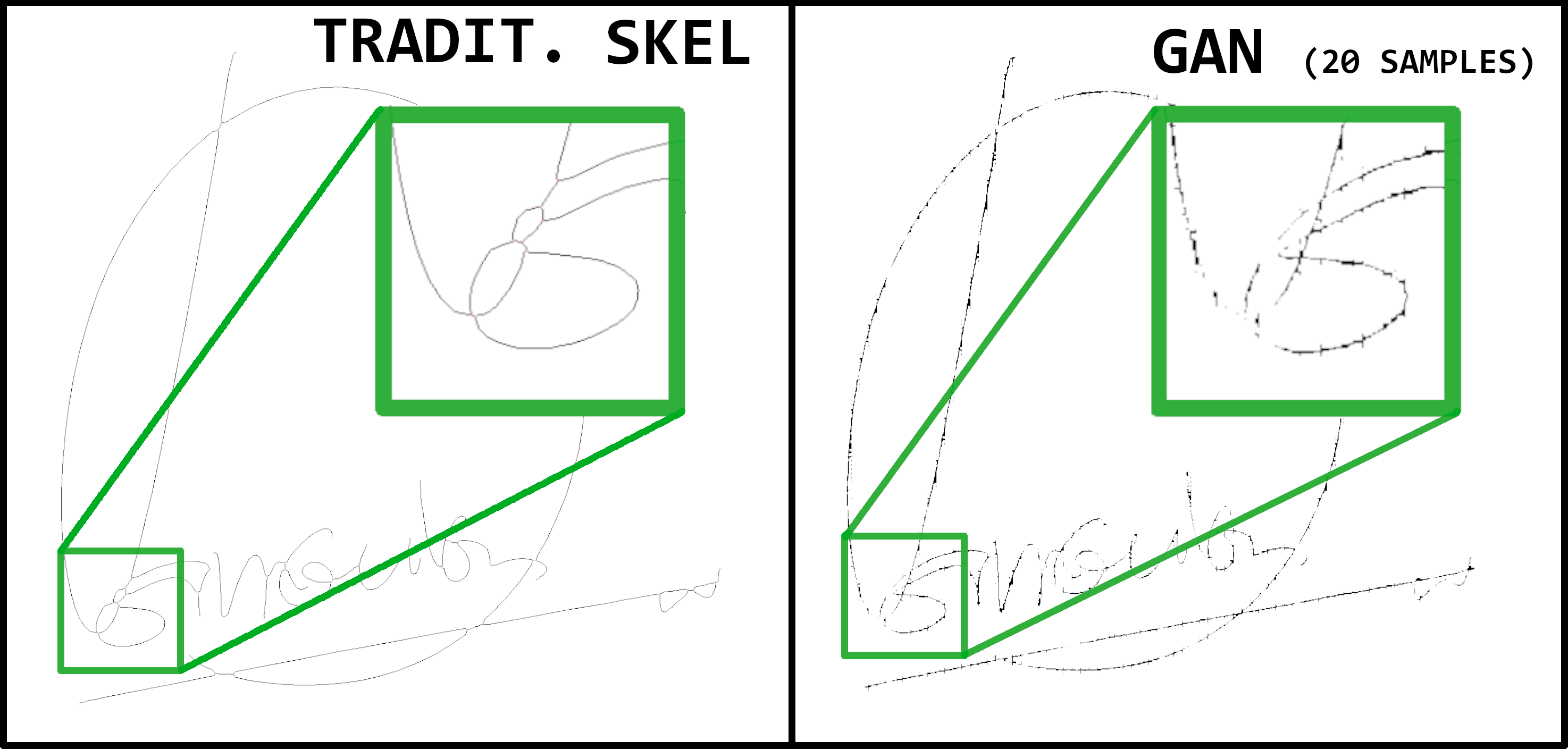
Fig. 4. Comparison between traditional skeletonization (left) and GAN based one (right). It could be seen that the latter better identifies how the intersections have to be drawn, though more training and post processing has to be done to get a clean result.
There is a lot of work to do, both as regards the collection of new data to expand the dataset, and for the analysis of the best hyperparameters. Finally, a minimum of postprocessing is probably required. Image cleaning steps, such as erosion or dilation are needed and perhaps, a further skeletonization step with traditional approaches could be useful to obtain a clean result.
Performance
Typically, GAN models do not converge; instead, an equilibrium is found between the generator and discriminator models. As such, we cannot easily judge when training should stop. This evaluation can be done by eye, looking at the images produced by the generator model and determining if the result obtained is in line with the expected performance. Indeed, this is the method that was used to choose the best model on this small dataset.
However, with specific reference to the skeletonization task, we can do better. For example, we can define a performance evaluation function that returns a numerical value that indicates the goodness of the transformation. The proposal is to make a pixel-to-pixel subtraction of the generated image with respect to the expected one and make the arithmetic average on all the generated-wait pairs of the test set. The value obtained can give us a general idea of how the generator model is performing. Also, the same function can be used to set up a hyperparameter optimization study.
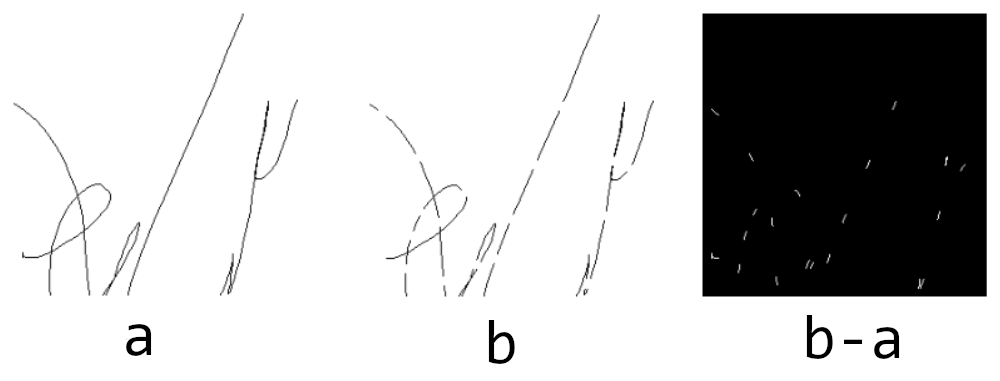
Fig. 5. A possible function to evaluate the GAN generation results
and understand which of the many can be the best model. The evaluation function is simply represented
by a pixel-to-pixel subtraction of the two images, the expected output and the generated one.
Conclusions
This is just a first attempt, the result of training on only 20 samples for 100 epochs.
As he will know, GANs are not easy to train; they require time and some fine-tuning.
Surely, one can do better with better datasets and hyperparameters.
I shared my code with the University of Salerno, to continue with the experiments on off2on
frameworks and improve this implementation.
In future, I hope to have the time to investigate the matter further
together with the University.