Experiment: Fake News Detection in browser
- Introduction
- Fake News Detection: Overview
- Experiment set-up
- Results
- Conclusion
Introduction
In the era of rapidly evolving digital landscapes and the constant influx of information, distinguishing between truth and falsehood has become a challenging task. The propagation of fake news, often designed to deceive and misinform, has raised concerns about the authenticity of the content we encounter online. To address this issue, we wanted to explore a novel approach - the creation of a Chrome extension for Fake News Detection, freely accessible to users. Compared to other Chrome extensions, our one is different as it performs neural network predictions directly in the browser.
This blog post delves into the experiment's objectives, methodology, and outcomes, shedding light on the possibilities and challenges of deploying deep learning models directly within a browser environment.
The experiment aims to comprehend the complexities involved in implementing a fake news detection system that not only replicates human cognitive processes but also operates within the constraints of real-time browsing. The endeavor acknowledges the inherent difficulty in distinguishing between genuine news and fabricated content, even for human experts. Despite the acknowledged challenges and potential performance issues, the results offer promising insights into the viability of such a solution.
For those interested,
- the Chrome extension can be downloaded and installed from the following link: Fake News Detector Chrome Extension;
- the project's GitHub repository can be accessed at: GitHub Repository;
- and the Home page of the project is available here: Home Page.
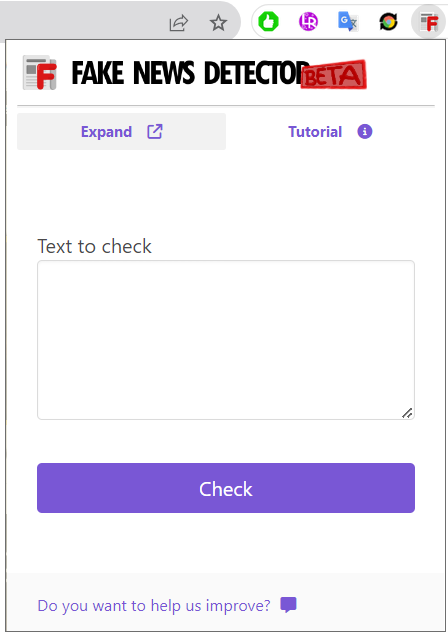
a. Popup of the extension. You can check your content directly from here.
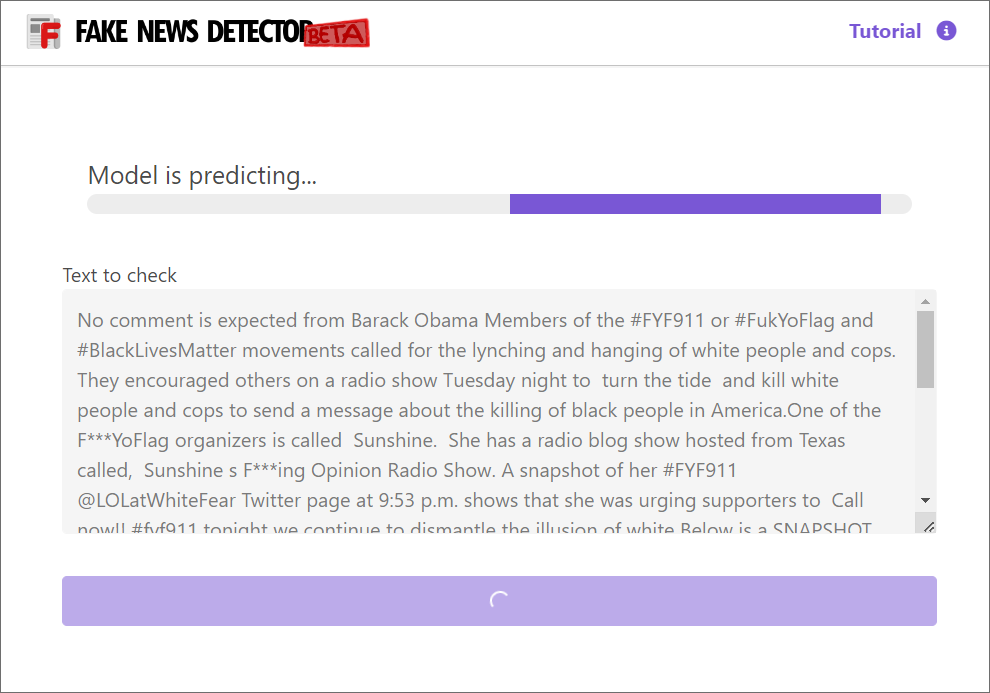
b. Main window of the extension. You can check your content using in bigger space.
Fake News Detection: Overview
Fake news detection involves the identification of misinformation or fabricated content presented as legitimate news. The proliferation of fake news can have far-reaching consequences, including influencing public opinion, undermining trust in media sources, and even affecting political landscapes.
Fake News detection is an incredibly hard challenge. The challenge lies in the nuanced nature of fake news, which often combines elements of truth with distorted or entirely false information.
Detecting fake news is complex due to several reasons:
-
Inherent Subjectivity: Differentiating between fact and fiction requires an understanding of context, semantics, and cultural nuances. Human biases can also cloud judgments, making it difficult for both individuals and algorithms to discern the truth.
-
Evolving Techniques: Those spreading misinformation continuously adapt their techniques, making it challenging to create a static model capable of identifying all forms of fake news accurately.
-
Diverse Content: Fake news encompasses a wide array of content formats, including articles, images, videos, and more. Each format demands a tailored approach to detection.
-
Limited Context: Many fake news detection models operate in isolated environments, lacking access to the broader context in which the information is presented. This limitation hinders accurate assessment.
-
Overcoming Cognitive Processes: Identifying fake news often involves critical thinking, source evaluation, and cross-referencing information. Replicating these cognitive processes in an algorithmic framework is a formidable task.
Given these challenges, the experiment of deploying a fake news detection model directly within a browser becomes all the more intriguing. It necessitates overcoming technical constraints while delivering results that are sufficiently reliable for real-world application.
In the next chapter, we will delve into the specifics of the experiment's set-up, including its purpose, the dataset used, and the chosen model for fake news detection.
Experiment set-up
Purpose of the experiment
The main purpose of this experiment was to create a completely offline in-browser Fake News detection through neural networks.
Besides being interesting from an academic point of view, this approach offers a number of advantages:
- increased privacy and security, as user data is not transmitted to external servers for processing.
- completely free to use, with no subscription fees or server costs.
The "Fake News Detection" Chrome Extension wants to be an innovative tool in the realm of fake news detection extensions, since it harnesses the power of neural networks while browsing the internet, unlike other fact-checking tools that rely on external databases or pre-written rules.
Dataset
Our Fake News Detection Chrome Extension uses the WELFake dataset, which is a collection of 72,134 news articles, containing 35,028 real and 37,106 fake news articles.
This dataset was created by merging four popular news datasets (Kaggle, McIntire, Reuters, and BuzzFeed Political) to prevent over-fitting of classifiers and provide more text data for better machine learning training. The dataset is comprised of four columns:
serial number(an identifier, starting from 0),title(about the news heading),text(about the news content),label(0=fake and 1=real).

Fig. 2. Overview of the WELFake dataset.
Model
To power our Fake News Detection Chrome Extension, we utilized MobileBERT, a highly efficient and compact variant of the popular BERT (Bidirectional Encoder Representations from Transformers) model. MobileBERT was specifically designed for use on mobile devices and web applications, making it a perfect fit for our browser-based extension.
To efficiently implement MobileBERT in our extension, we used ONNX (Open Neural Network Exchange), an open-source format for representing deep learning models that enables interoperability between different deep learning frameworks. ONNX allows for the exchange of models between popular frameworks such as TensorFlow, PyTorch, MXNet and more, which facilitates the deployment of models across different platforms and environments.
Furthermore, as discussed in another blog post, ONNX can optimize performance of neural network predictions, therefore is highly recommended in production environments or applications with low-resources requirements. ONNX indeed offers quantization, pruning and other techniques to improve network size and inference times.
To execute ONNX models in a browser environment, we utilized ONNX.js, a JavaScript library that provides a runtime for ONNX models directly within the browser.
By combining MobileBERT with Onnx.js, we are able to perform fast and accurate inference directly within the browser, and thanks to them, we can offer ths extension without the need for paying external servers or cloud computing.
Results
Even if the premises are good, we acknowledge that one of the main challenges with fake news detection is the lack of adequate coverage of news articles in certain domains, such as technology. There is a risk that the classifier may flag some genuine articles as fake news, even if they are from certified sources.
Additionally, the size of the dataset is relatively small, which may lead to limited coverage of certain types of fake news. We are actively exploring ways to improve the dataset and enhance the accuracy of our predictions.
Furthermore, it's important to note that due to the limited scope of the WELFake dataset, the Fake News Detection Chrome Extension currently only supports English language articles.
We are working to expand the dataset and enhance the language support in future releases of the extension.
Additionally, the use of a complex model like MobileBERT in a browser environment can sometimes lead to slow downs and performance issues while browsing.

Fig. 3. Example of a positive prediction - correctly identified as authentic news.

Fig. 4. Example of a negative prediction - correctly identified as fake news.
Conclusion
This project was born as an experiment, with academic purposes in its first instance. Nevertheless, we gave it much more effort, trying to make it a potentially usable tool.
Therefore, we are proud to release our Fake News Detection Chrome Extension in beta, as we think that it offers a valuable basis for identifying potentially misleading content online and makes the users more conscious of what they are reading.
While our initial release offers accurate detection in many cases, we recognize that there is still room for improvement.
We know that fake news detection is a complex and challenging task, requiring ongoing refinement and adaptation to address new types of misinformation.
Today, advanced networks such as ChatGPT, llama, etc. are master in creating human-like content and our method,
based on MobileBERT and designed to be lightweight, can hardly compete.
Also, running neural network prediction in browser, even if optimized used modern quantization and pruning framework such as Onnx.js, can lead to a bad
browsing experience, as they require lots of memory and resources.
We believe that it is a great starting point, with a higher potential with respect to rules-based approaches that cannot be up to dated and responsive to the newest trends. We hope that in future browsers could be more powerful and we look forward to seeing more sophisticated network developed to address Fake News detection. Thus, we are committed to ongoing development and improvement of our extension, and welcome feedback from users to help us enhance its effectiveness and accuracy.