A novel Writing Order Recovery approach for handwriting specimens
- Introduction
- Why writing order recovery?
- The idea
- Results
- Conclusions
Introduction
This post summarizes the work and ideas behind my thesis work, which became a publication at the 16th International Conference on Frontiers in Handwriting Recognition (ICFHR) at Niagara Falls, USA, in August 2018 (see here), and another journal article is in the works.
The following video shows the results of my work.
Why Writing Order Recovery?
Before clarifying what Writing Order Recovery is, let's give some context.
In the area of digital signature verification, there is the problem of evaluating the authenticity of a writer based on the writing. Now, if the signature is digitally acquired (online writing), we have access to a lot of information, as it is possible to record all the movements that the writer makes. If the signature has been acquired analogically (offline writing), i.e. on paper using a pen, the task becomes extremely difficult. Nowadays, most signatures are still done without digital devices.
Techniques have therefore been born that allow us to infer the writing dynamics through pattern recognition and machine learning algorithms. By «writing dynamics» we mean all information related to speed, pressure, writing tracing order, etc. All this information is essential to carry out a more accurate signature verification and at the same time the technique can be used in other fields such as handwriting recognition and so on.
In the article, the authors (Moises Diaz, Miguel A. Ferrer, Antonio Parziale and Angelo Marcelli) proposed a framework for obtaining the dynamics of a handwriting stroke starting from a static image. The Writing Order Recovery (WOR) is positioned as the second step of this framework and its goal is to infer the writing order. Among all, the writing order is the most informative and preparatory element for estimating the other dynamic components such as speed and acceleration. I have decided to concentrate on this delicate step and reapproach the problem by providing a new point of view and a new way of solving it (here the code).
The idea
As expressed by the framework mentioned above, the first step for Writing Order Recovery is to perform a thinning on the image, in order to have a track composed of only one pixel. In fact, the image acquired with the pen is a dirty, double trace, and reconstructing the writing order is more difficult.
The class of algorithms used to produce this thin trace is called skeletonization.

Fig.1. Comparison between the the Real Image (a), the binary one (b) and the skeletonized one (c). Image from Recovering Western On-line Signatures FromImage-Based Specimens
What I noticed right away is that, whatever the method used, skeletonization produces artifacts and non-existent lines that break down the performance of the algorithms of the subsequent steps. This observation is almost trivial: since no information on dynamics is available, even for skeletonization it is difficult to produce quality results. For this reason, I decided to apply the ideal skeletonization, the best possible, obtainable through the Bresenham algorithm. This algorithm produces a thin track by exploiting the dynamics with which it was performed. It is the perfect basis for developing a good Writing Order Recovery algorithm.
Let's enter in the interesting part. The Writing Order Recovery algorithm I proposed consists of 3 parts:
- Point classification
- Local Examination
- Global Reconstruction.
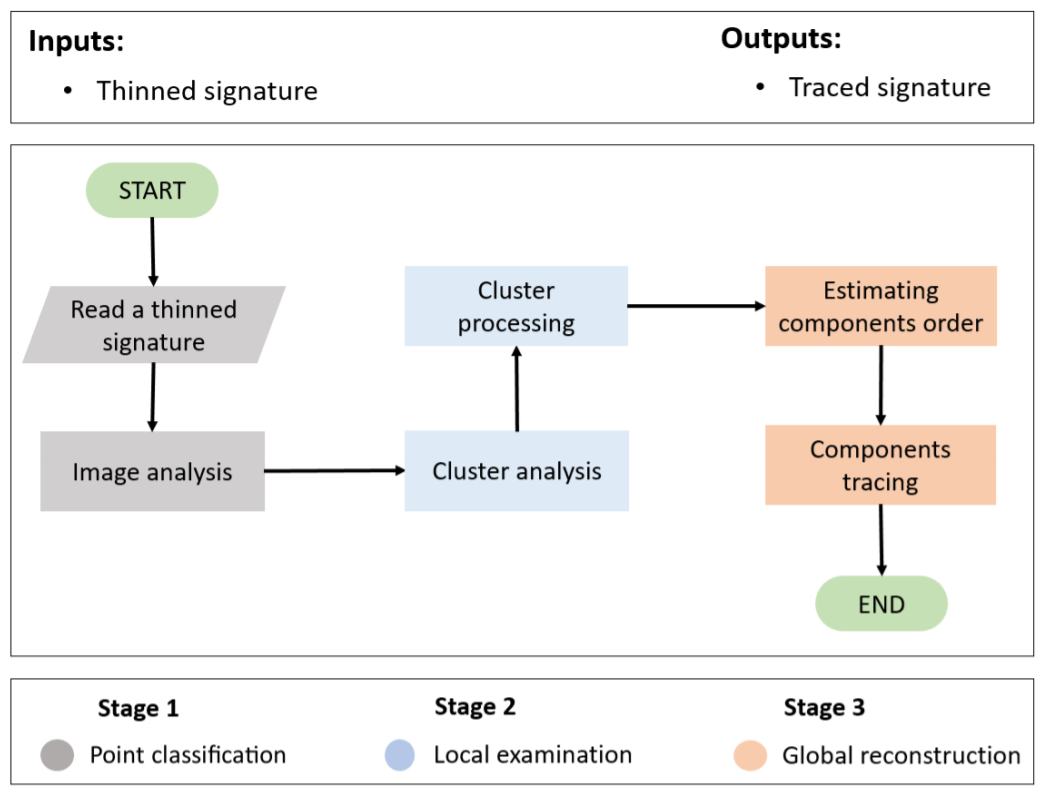
Fig. 2. Phases of which the algorithm is composed.
Point Classification
The Point Classification phase deals with analyzing the thinned signature pixel by pixel. Pixels are classified according to their neighbors: if a pixel has only one other neighbor pixel it is considered an end point; if a pixel has two neighbors it is considered a trace point and if it has 3 or more it is defined as a branch point. Agglomerations of branch points form a cluster of points. The innovation is here: clusters are the "hard part" and this is where I have concentrated my efforts.
In the literature we rarely speak of "agglomerated points". This is because we usually work on imperfect skeletonization algorithms, which never produce lines thicker than 1 pixel, in order to simplify the work of writing order recognition: however, there is a huge loss of information.
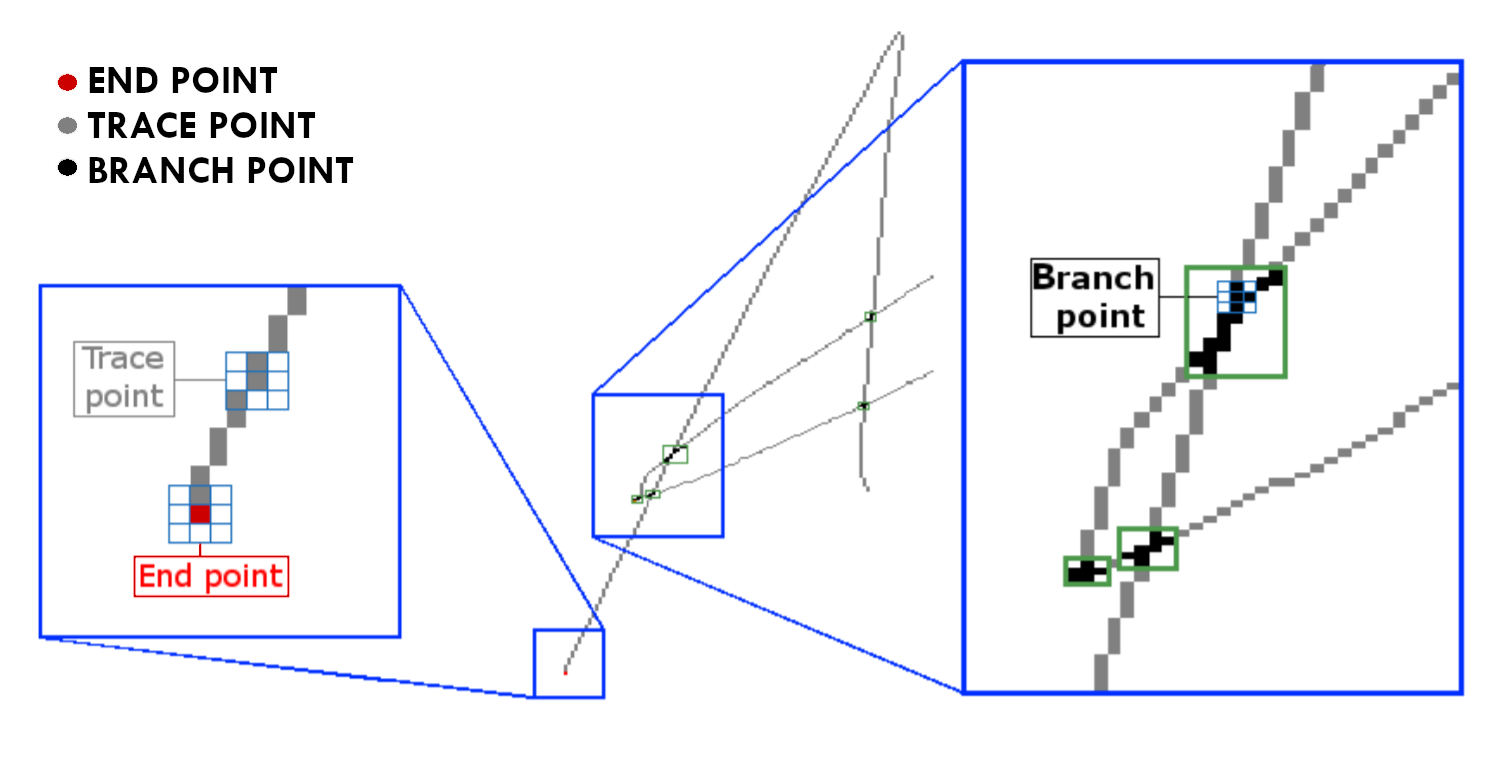
Fig. 3. Point classification. It depends on the number of neighboring pixels for each pixel.
Local Examination
The Local Examination phase focuses on the analysis of branch point clusters. Among them there are some particular points: those in contact with a trace point are called anchor branch points and overlook an outgoing branch from the cluster (see the Fig. 4). Indeed, a cluster can be seen as the intersection point of multiple lines. The goal is therefore to understand how to match the outgoing cluster branches and correctly reconstruct the paths that the writer's pen has performed.
To understand how to couple these output branches, we calculate the internal angles of the cluster, the external angles, we perform a prediction of their direction through multiscale analysis algorithms and finally we calculate the matching through pattern-recognition algorithms. To make the article streamlined and easier to follow, I leave out the details you find in the paper at this link.
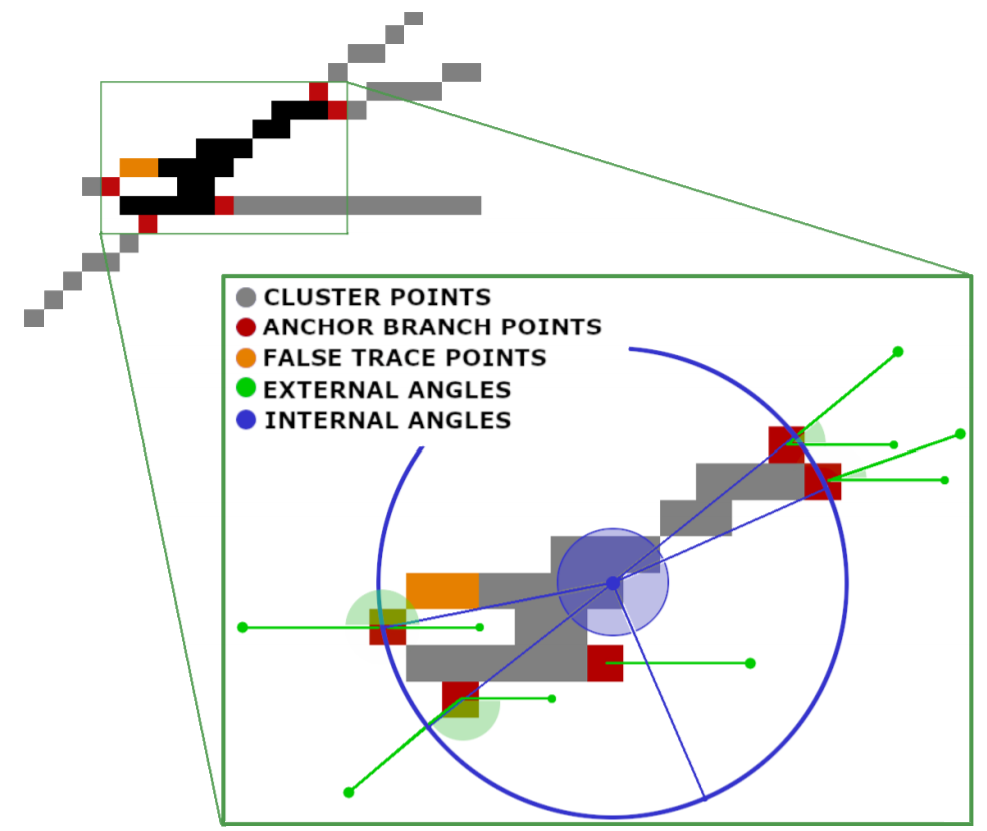
Fig. 4. Cluster analysis. In this phase we search for anchor branch points and we compute the angles to find the cluster output branches associations.
Once we have rebuilt a cluster, i.e. associated its exit branches, we know how a track enters and exits the cluster. So we can reconstruct the signature.
However, a writer can make several strokes, lifting the pen from the sheet multiple times. Another task of writing order recovery is to correctly identify the so-called components. A component is therefore a stroke of writing performed without ever lifting the pen from the sheet. Identifying them is not easy. In general, we use end points, i.e. those points that have only one neighbor, so it is reasonable to think that the stroke started from there. Anyway, this approach is not enough; with the information obtained from the clusters we can better infer when a writer stops his pen or when he continues.
Global reconstruction
Once the cluster have been rebuilt and the components have been individuated, we can proceed with the Global Reconstruction of the signature. This means trying to infer the writing direction of each single component (for example from left to right or top to bottom, etc) and the order of the components, then understand in which order they were traced by the writer.
This is by no means a simple task. Without information about the current signature, we can only guess using heuristics or predictive algorithms trained on other data. However, every writer has their own writing method, so there is no 100% reliable solution. The heuristics I used were basically two:
- for the first component, start from the top left corner, assuming that most writers write from left to right;
- for the following components, choose the closest one according to the Euclidean distance.
Below, an image that clarify what are the components (indicated by different color) for each signature and how they were traced by our algorithm (shown by the arrows).
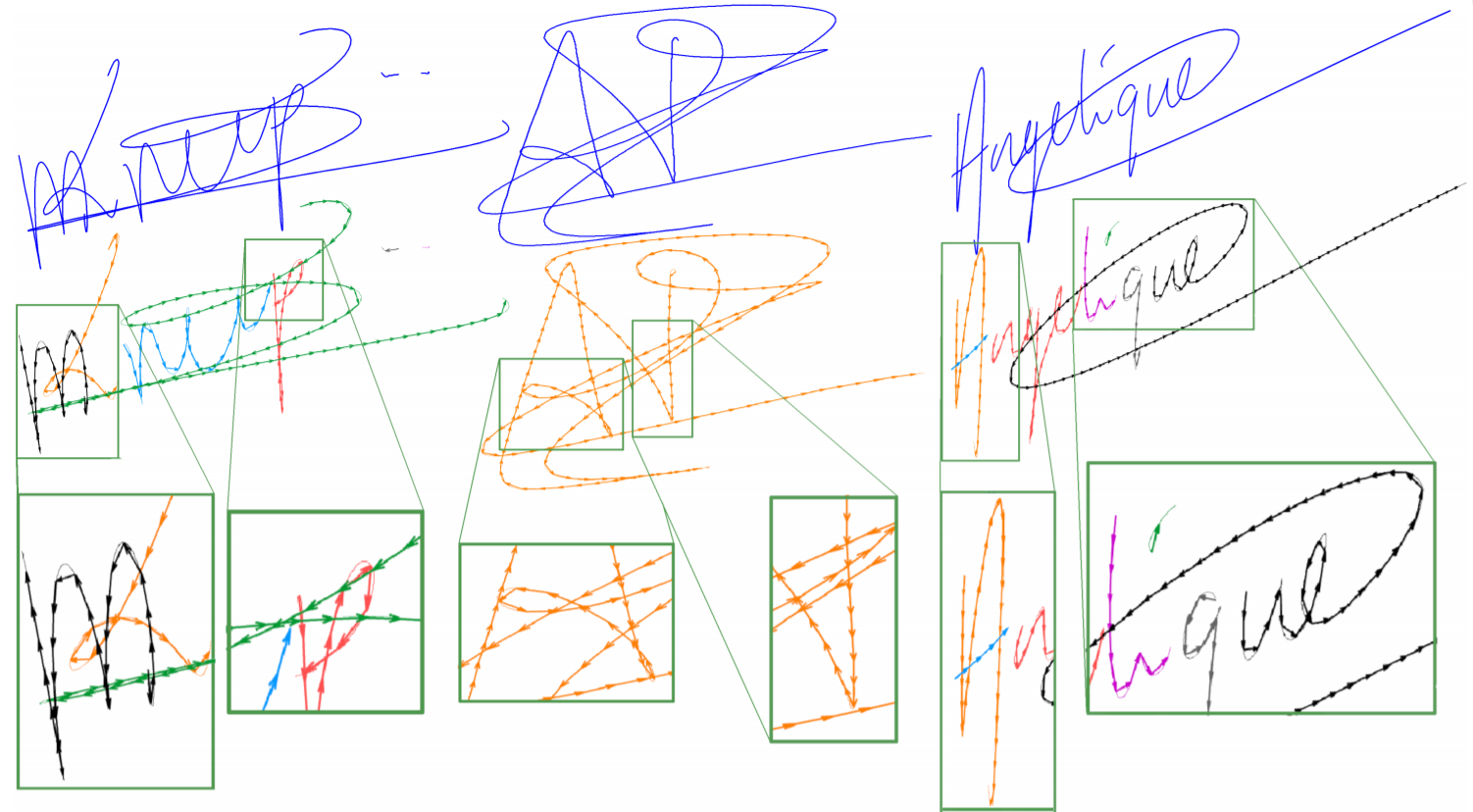
Fig. 5. Global reconstruction. We find all the components (indicated by different colors) in the signature and then we trace them.
Results
The method proposed above was performed on two datasets, SUSIG-Visual and SigComp2009, demonstrating the independence of the algorithm from the dataset and from the writing method of each writer.
To evaluate the goodness of the method, we used the classic sequence comparison metrics: Signal-to-Noise Ratio (SNR), Dynamic Time Warping (DTW) and Root Mean Square Error (RMSE), to evaluate our reconstruction with respect to the real signature. In the following table, and we compare ouu method with other methods present in the literature.
Finally we proposed a new metric for clusters, the heart of our work, by defining the accuracy of the reconstructed clusters as the ratio of correctly reconstructed clusters to the number of all clusters. We talk about Cluster Rebuilding Percentage (CRP). A correctly rebuilt cluster is a cluster for which all branches outgoing from it have been successfully paired (i.e. traversed in the direction in which the writer traced them).
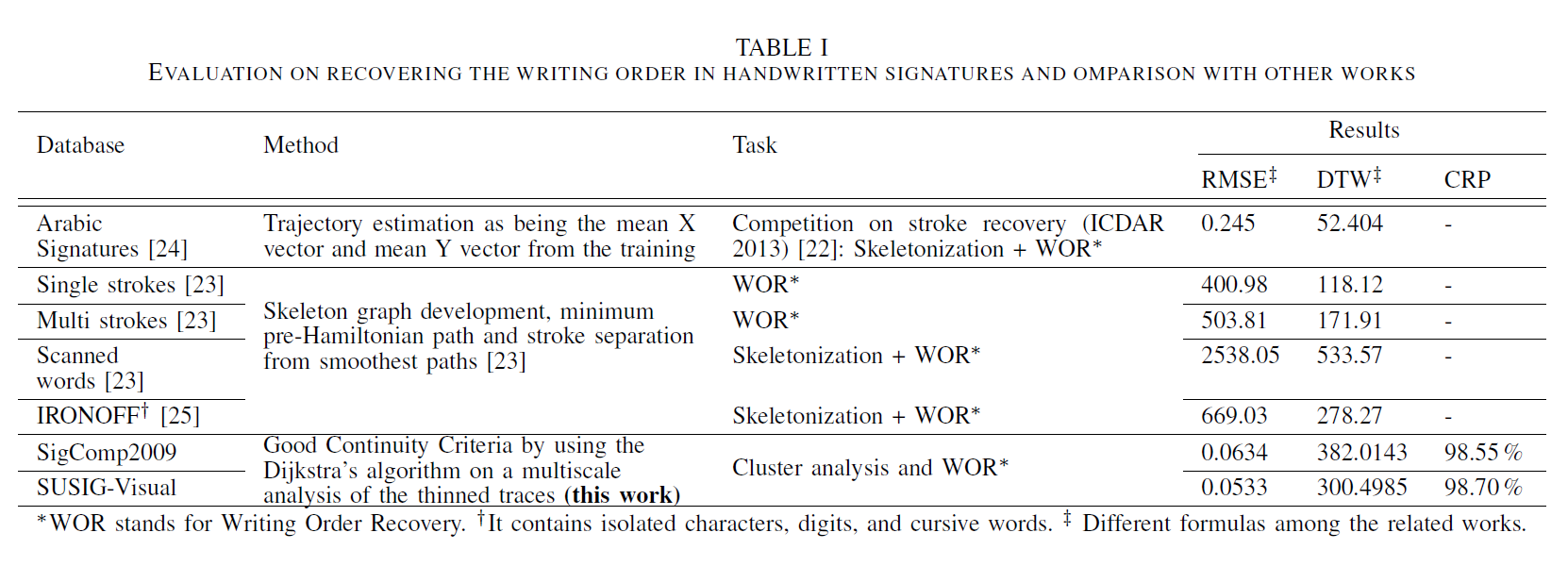
Table. 1. Comparison with other methods. We have added also the CPR measure since the core of our work is the cluster analysis.
Experimentally, we have noticed that some signatures are more difficult than others. This is mainly due to the fact that the writer could cross a line several times, making overlaps. We therefore deemed it necessary to divide the dataset into three complexity classes (low, medium, high) and evaluate the results separately. We have defined complexity as a parameter that depends on the number of clusters and components in the signature: the more clusters and components there are in the signature, the more difficult it is.
The good results obtained show that:
-
using an ideal skeletonization helps a lot, since there is no loss of information and a more in-depth analysis on the signature can be conducted;
-
clusters of branch points give a lot of information on how a signature has been traced, allowing to correctly infer the tracing direction. We have seen that the more clusters are reconstructed correctly the more likely the signature is reconstructed correctly, so they are a key point for the writing order recovery task.
-
easy signatures, with few clusters and components, are almost always reconstructed in the right way.
Conclusions
This work proposes a new approach based on pattern recognition for the execution of Writing Order Recovery, highlighting through the good results obtained that:
-
the skeletonization phase must be greatly improved to allow the subsequent phases to work on good quality data;
-
a good point and trace analysis performed locally may be sufficient to estimate the writing order, without resorting to computationally expensive algorithms that operate globally.
In fact, the proposed algorithm works locally, compared to many algorithms, proposed in the literature, which work considering the image as a whole. The latter, besides being more complicated and expensive, are also less reusable for different types of writing (for example oriental writing, Arabic writing, numbers).
The algorithm has several margins for improvement: in addition to refining the pattern detection metrics, it could use other Machine Learning techniques such as the Kalman filter or more complex tracking clueing techniques to estimate the correct exit direction of a cluster.