A complete ML Pipeline study case: Face and Emotion recognition
- Introduction
- The study case: Face and Emotion recognition with a CNN
- Do not forgive Optimization
- Prepare for production with ONNX
- Conclusions
Introduction
This post describes a project I made with my girlfriend, aiming to perform face and emotion recognition through a Kinect sensor or a generic webcam.
The emotion supported are: Happy, Sad, Disgust, Neutral, Fear, Angry,
Surprise. The depth camera of the Kinect Sensor is used to carry out Depth
Segmentation and reduce face detection false positives. In addition, a confirmation
window is used to stabilize the model's predictions.
The model used is a CNN built from scratch and trained on FER 2013 Dataset. Then, an optimization phase has been performed to obtain the best hyperparameters. The following video shows the results of our work.
The study case: Face and Emotion recognition with a CNN
In this section, we describe the step we followed to train the face recognition and emotion recognition models and use them on a video stream capture from a Camera / Kinect.
Face Detection and Recognition: Dataset acquisition
To train face recognition we created a script that allowed us to collect images of a person's faces. The script must be configured by passing as parameters the name and the number of photos to be saved. The process uses opencv's face detector to automatically extract faces and save them by labeling with the name entered. This also allowed us to quickly review the saved photos and delete dirty data if any. To have good recognition performance we used about 100 photos per person; results clearly vary in different lighting conditions.
Face Detection and Recognition: Train and evaluation
The training of opencv's LBPHFaceRecognizer is very quick. We trained it on two different faces, but it's scalable on multiple faces.
For the inference phase we used the labels extracted from the LBPHFaceRecognizer of opencv trained as described in the previous point to create Confirmation Windows for each person and then isolate the emotions based on the detected face. More details on the Confirmation Windows will be given later.
Emotions Recognition: Data Exploration and Processing
We used FER2013 dataset. As a first step, we analyzed the dataset to verify its distribution and check its content, displaying some images.
We noticed that it is a very difficult dataset, since it has 3 main issues:
- It is very unbalanced, as shown in Fig. 1;
- The images it contains are dirty (some images are cartoons) or have noise (for example writing or hands on the face). Refer to images contoured by red and blue rectangles in Fig. 2;
- Some images could be misclassified (e.g. some emotion tagged as "fear" could be classified as "surprise"). Refer to images contoured by green rectangles in Fig. 2.
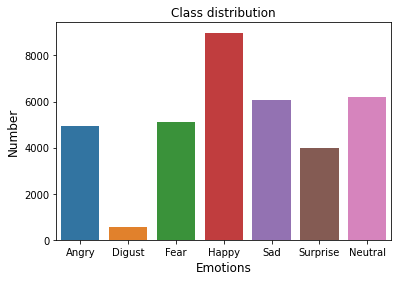
Fig. 1. Distribution of the dataset. There is a predominance of "Happy" and "Neutral"
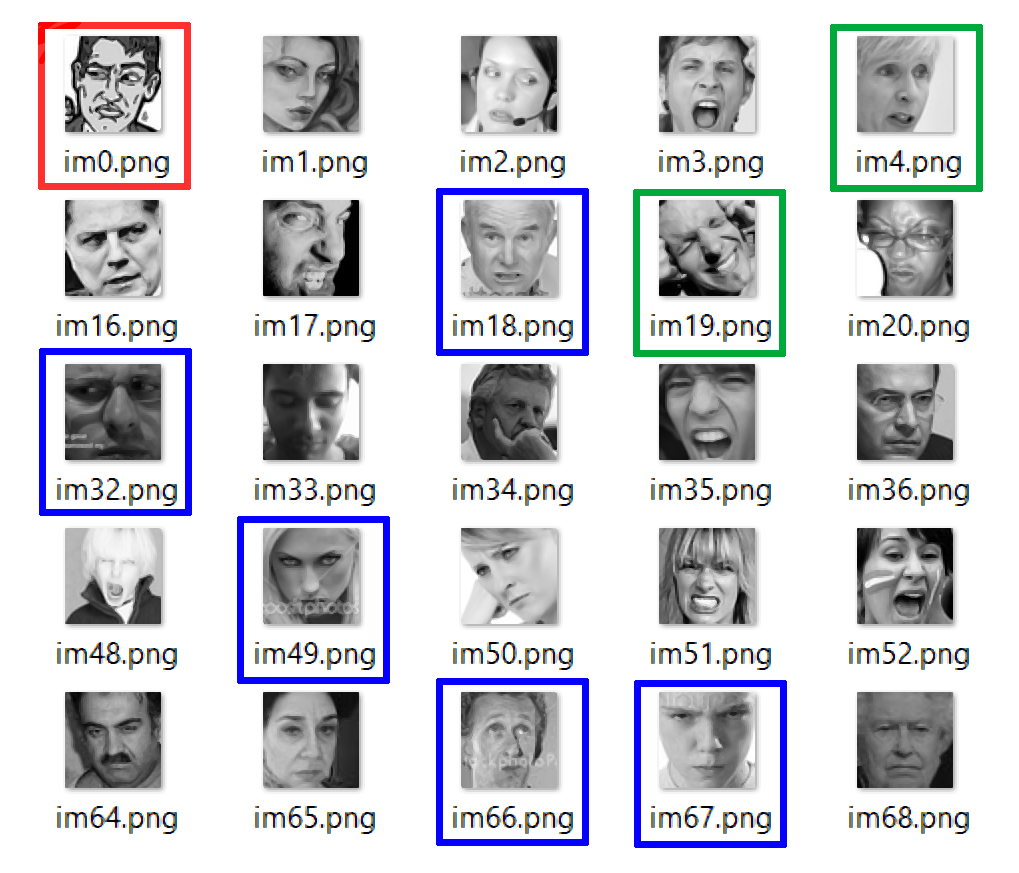
Fig. 2. Some examples of images belonging to "Angry" emotion.
The red rectangle indicates an image taken from a cartoon. The blue rectangles are around images soiled by writing.
Finally, it is difficult to say if the woman in the green rectangle on the right is angry or shocked; the emotion of the man on the second row on the right could be considered also "Happy".
In fact, as mentioned in this paper (sec. III), the human accuracy on this dataset is about 65%.
The dataset is already divided into train, validation and test and we made sure that the three sets had the same distribution. We then decided to merge the train and validation sets together, in order to be free in choosing the percentage to be allocated to the validation set.
Finally, we decided not to use oversampling techniques and to use the as-is dataset, to try to get the most out of the CNN network and the training process, without adding new data.
Emotions Recognition: Training and Evaluation
We used a CNN built from scratch, consisting of four convolution layers and two dense layers. We verified that the model was sufficiently powerful and we managed overfitting with regularization techniques such as l2 and dropout.
The dataset has been divided into 70% for training, 20% for validation and 10% for testing,
respectively. In the training phase, we used Keras' ImageDataGenerator utilities
to do some data augmentation and add zoomed and horizontally mirrored images.
This allowed us to increase the test performance a bit.
We have optimized the hyperparameters of the model through the use of Optuna;
details on hyperparameters and ranges will be given later.
In the evaluation phase, we plotted a normalized confusion matrix to understand the performance of the model relative to each class. The results were what we expected: a strong polarization towards the most populous classes and an average error spread across all them. In fact, the performance mirrors the challenges of the dataset.
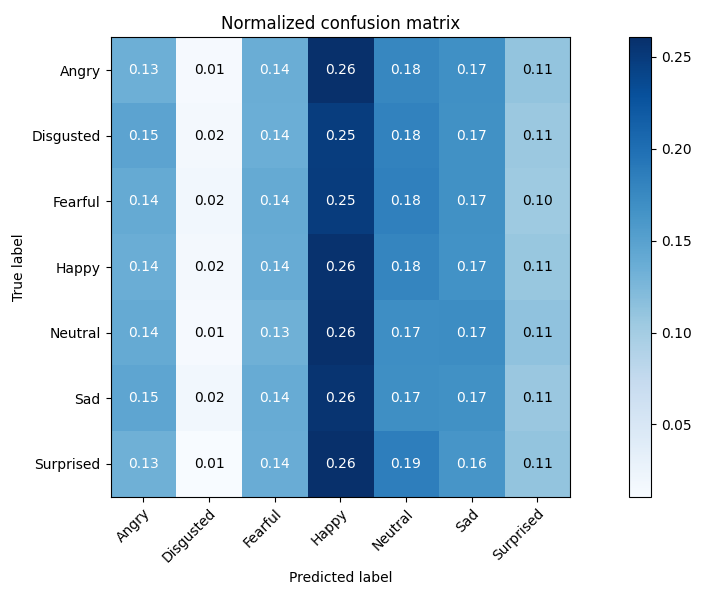
Fig. 3. Confusion matrix after the optimization phase.
Improvements for real use
Given the poor performance of the model and considered the fact that the images acquired by a webcam may be "different" from those present in the dataset, we decided to add some "improvements" for real use. We first introduced a Confirmation Window, to stabilize the model predictions over a higher frame number. The confirmation window, implemented as a queue, collects the emotions of the last 20 frames and returns the value only if the dominant emotion is present in more than 60% of the frames. If this condition is not satisfied, "Neutral" is returned, indicating that the model is not fully convinced of the emotions collected in the last 20 frames.
A confirmation window is associated for each recognized person, so as not to mix predictions related to different faces. The benefit this implementation has brought is that the feeling that the model is wrong has drastically reduced.
Building Freenect and the python wrapper
The code can run also on a generic camera, but we used the Kinect to take advantage of the depth sensor to decrease false positives. We built its drivers on Mac OS, based on the Homebrew method described at the following link: https://openkinect.org/wiki/Getting_Started#OS_X. With Homebrew you can easily install the Kinect v1 drivers.
Kinect's depth camera helped us to segment and filter objects based on depth. This allows us to reduce the number of false positives of face detection. Since there is no rejection threshold for face recognition, limiting false positives also allows the predictions contained in the confirmation window to be "not dirty", thus resulting in a reliable prediction.
Do not forgive Optimization
After deciding that the chosen model had performances in line with what was expected, we moved on to the optimization phase, to obtain better hyperparameters and therefore a higher accuracy. We used optuna, an optimization framework specifically designed for this task.
The hyperparameters we have optimized are:
'lr': learning rate, uniform distribution from 1e-5 to 1e-1,
'decay': lr decay, uniform distribution from 1e-7 to 1e-4,
'dropout': uniform distribution from 0.10 to 0.50,
'l2': l2 regularization in Conv2D layers, uniform distribution from 0.01 to 0.05,
'kernel_size': for Conv2D layers in range [3, 5],
'batch_size': in range [16, 32, 64, 128],
The best hyperparameters, found in 50 iterations, are:
'lr': 6.454516989719096e-05,
'decay': 4.461966074951546e-05,
'dropout': 0.3106791934814161,
'l2': 0.04370766874155845,
'kernel_size': 2,
'batch_size': 32,
with a test loss of: 1.0534, and test accuracy of: 66.035%.
The optimization phase added a few percentage points to the average accuracy; however we
can affirm that the perceived performances are much higher. The advice we give is
therefore not to forget the optimization phase; 4-5 percentage points are not many and do
not upset the performance of a poor-performing model, but they can still make a difference.
Prepare for production with ONNX
To speed up the inference phase, we setup up the ONNX conversion and runtime tools. After choosing the best hyperparameters for the emotion model, we trained it and got an optimized Keras model. So we converted it to a ONNX model. Generally speaking, the ONNX model version is much faster than the Keras one. This leads a less power consumption and a higher FPS for our video application. On our machines (CPU based, no NVIDIA), the ONNX model is around 25x faster than keras version.
These are the results:
Keras predictor 100 times - Elapsed: 3.177694320678711; mean: 0.03177694320678711
ONNX predictor 100 times - Elapsed: 0.119029283523559; mean: 0.00119029283523559
Factor: 26.696.
Keras predictor 10000 times - Elapsed: 317.5036771297455; mean: 0.03175036771297455
ONNX predictor 10000 times - Elapsed: 11.5271108150482; mean: 0.00115271108150482
Factor: 27.544.
Conclusions
Although the recognition of faces and emotions is not a new topic, it was interesting to approach a challenging dataset, applying all the best practices that are used to bring a solution into production. The task was difficult mainly due to the implications of using a very unbalanced, very heterogeneous dataset with few samples. We did a statistical analysis, but decided not to oversample and treat the dataset as it was. In order not to make things easier for us, we have decided not to do transfer learning from a pre-trained model.
The optimization phase was fundamental to obtain an accuracy of approximately 5% more. Although, accuracy is not perfectly indicative of such an unbalanced dataset, the model's perceived performance after optimization was much more satisfactory. The use of confirmation windows also made a big difference; they are not a new technique, but they help tremendously in correcting false positives and increasing perceived performance. Finally, the use of ONNX was important to achieve a performance boost on the CPU and make the application usable in real time, reaching an average of 30 frames processed per second on discrete computers.